

모바일 다음에서 뉴스기사를 검색하면 아래와 같은 URL로 접속됩니다.
https://m.search.daum.net/search?w=news&q=인공지능
최대한 간단히 줄인 주소입니다.
PC웹에서 검색해도 비슷한데 효율성을 위해서 모바일 검색을 기준으로 알아봅니다.
다음에서 검색에 대한 API를 제공하지만 신문사를 조건으로 검색하는 등의 상세한 기능은 지원하지 않아 Http문서를 크롤링하는 방법을 이용합니다.
검색 결과 형태는 아래와 같습니다.

HTML 구조를 살펴보면 아래와 같습니다.
주황색 네모 영역이 기사제목이고 파란색 네모가 제목내용이 들어 있는 태그입니다.

태그의 여러 정보를 가져올 때 GetElementsByClassName 이나 GetElementsById 등을 이용할 수 있는데
여기서는 QuerySelector 나 QuerySelectorAll 을 이용해보겠습니다.
전자는 하나의 클래스 이름이나 ID로 해당 태그를 가져올 수 있는데
후자는 여러개의 클래스 트리 구조로 태그를 찾아올 수도 있고 특정 조건을 명시해서 조건에 부합하는 태그만 가져올 수도 있습니다. 특히 전자는 같은 클래스 이름이 여러 개일 때 가져오려면 여러 단계를 거쳐야 하지만 후자는 태그나 클래스 이름을 트리구조로 찾아 들어가서 한 번에 해당 속성 값을 가져올 수 있는 장점이 있습니다.
예를 들어 <div 태그 안에 <a 태그 안에 <strong 태그 안으로 찾아 들어간다면 QuearySelector("div > a > striong") 으로 세 개의 조건을 모두 부합하는 태그만 가져올 수 있습니다. 또한 클래스 이름인 경우는 QuearySelectorAll(".className1 > . className2 > .className3") 이런식으로 .className 형태로 점만 앞에 붙여서 다중 조건으로 태그를 가져올 수 있습니다. Id인 경우는 #idName 으로 바꾸면 됩니다. 마치 정규식처럼 querySelector("div.user-panel.main input[name=login]"); 같은 복잡한 조건도 가능합니다.
여러가지 자세한 Selector 문법은 링크를 참고하세요. (querySelector의 단점은 getElementBy~는 동적으로 실시간 업데이트 되지만 querySelector는 정적인 요소라는 점입니다.)
QuerySelectorAll 은 해당하는 모든 요소 배열을 리턴하고 QuerySelector 는 해당하는 첫번째 요소만 가져옵니다.
doc.querySelectorAll(".item-title")은 위의 주황색 네모 div 들을 모은 컬렉션입니다.
즉, item-title 이라는 클래스명을 가진 Div 들의 목록입니다.
그 안의 텍스트는 추출이 됩니다.
하지만 링크는 그 안에 있는 파란색 A 태그 부분에 달린 속성값입니다.
그래서 가져올 수 없게 됩니다.
1. 아래처럼 한 번 더 querySelector로 그 안에 Tag를 찾아들어가거나
doc.querySelectorAll(".item-title").Item(i).querySelector("a").href
2. 아니면 처음에 querySelectorAll 로 태그를 가져올 때 아래처럼 가져오는 등의 방법이 있습니다.
doc.querySelectorAll(".item-title > strong > a")
이렇게 하면 item-title 클래스 아래> strong 태그 아래> a 태그들을 찾아옵니다.
2번 방법의 코드와 샘플 파일은 아래 지식인 답변을 참고하세요.
https://kin.naver.com/qna/detail.naver?d1id=11&dirId=1128&docId=485457422&answerNo=1
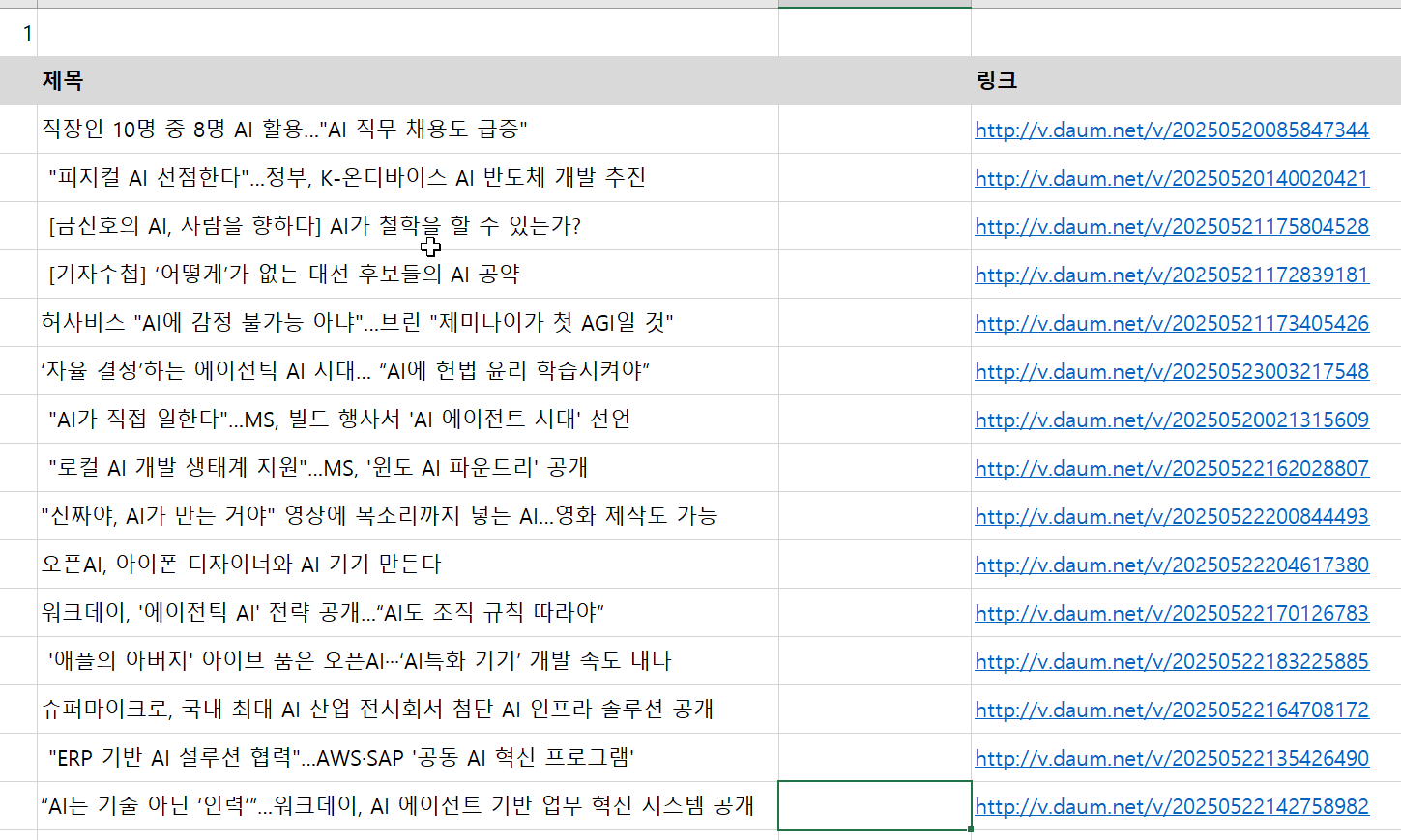
여기서 다음 뉴스의 신문사, 제목, 썸네일, 날짜 등을 가져오는 조금 더 체계적인 방법을 알아봅니다.
- 모바일 주소로 접속하는 것이 살짝 더 효율적일 수 있습니다.
- 내부에 JSON 데이터가 들어 있는데 이 데이터를 이용하는 것도 좋습니다.
- 언론사, 날짜, 썸네일 등도 추출해야 한다면 좀 더 사이트 HTML 구조에 맞게 체계적으로 접근하는 것이 좋습니다.
<UL>
<LI>
<LI>
<LI> ...
</UL>
이런식으로 기사들이 나누어져 있으므로 이 구조대로 읽어들여서
필요한 정보를 빼내는 것이 좋습니다.
먼저 HTML구조를 살펴보면 <UL> 태그 아래에 각 기사마다 <LI>태그로 분리됨을 알 수 있습니다.
이 구조 대로 HTML을 가져오는 것이 좋습니다.
그리고 노란색 클래스 이름이나 태그이름을 이용해서 각 문자열값을 가져올 수 있겠습니다.

주요 코드만 나열하면 아래와 같습니다.
r = 3
For p = 1 To Page
url = "https://m.search.daum.net/search?nil_suggest=btn&w=news&cluster=y&q=" & KeyWord & _
"&p=" & p & IIf(sort = "", "", "&sort=" & sort)
With http
.Open "get", url, False
.setRequestHeader "User-Agent", "Mobile" '"Mozilla/5.0 (Linux; Android 6.0;) AppleWebKit/537.36 Chrome/120.0.0.0 Mobile Safari/537.36"
.send
doc.body.innerHTML = .responseText
'Debug.Print .responseText
End With
Set elem = doc.querySelectorAll(".c-list-basic > li")
If elem.Length < 1 Then Exit Sub
For i = 0 To elem.Length - 1
Cells(r, "A") = r - 2 '연번
'언론사
newsFrom = elem(i).querySelector("strong").innerText '첫번째 strong 태그
Cells(r, "B") = newsFrom
Cells(r, "B").NumberFormat = " @" '왼쪽 한 칸 여백
'날짜
newsDate = elem(i).querySelector(".gem-subinfo").innerText
Cells(r, "C") = Split(newsDate, " ")(0)
' 뉴스 제목
newsTitle = elem(i).querySelector(".item-title").innerText
Cells(r, "D") = newsTitle
Cells(r, "D").NumberFormat = " @"
'뉴스 링크
newsLink = elem(i).querySelector(".item-title > strong > a").href
If newsLink <> "" Then
Cells(r, "F") = newsLink
Cells(r, "F").Hyperlinks.Add Anchor:=Cells(r, "F"), Address:=newsLink, TextToDisplay:=newsLink '링크 삽입 위치
End If
'썸네일
If elem(i).querySelectorAll(".wrap_thumb > a > img").Length > 0 Then
newsThumb = elem(i).querySelector(".wrap_thumb > a > img").getAttribute("data-original-src")
Else
'썸네일 없는 경우 언론사 로고
newsThumb = elem(i).querySelector(".wrap_thumb > span > img").getAttribute("data-original-src")
End If
With Cells(r, "E")
If newsThumb <> "" Then
Set shp = sht.Shapes.AddPicture(newsThumb, msoTrue, msoFalse, .Left + 1, .Top + 1, .Width - 2, .Height - 2)
shp.Name = "Pic_" & Format(r - 2, "000")
shp.AlternativeText = newsLink
End If
End With
'잠시 대기
If (r - 2) Mod 3 = 0 Then _
Application.Wait Now + TimeSerial(0, 0, 1)
r = r + 1
Next i
Next p
검색결과:

그런데 특정 신문사 기사만 검색할 때는 문제가 생깁니다.
일단 각 신문사의 CpCode 값을 알아야 합니다.
CpCode라는 별도의 시트에 가나다순의 신문사 이름과 CpCode값을 가져오는 코드입니다.
Sub getCpCode()
Dim sht As Worksheet, rng As Range
Dim http As Object, JSON As JsonBag, str$
Dim url$, c As Variant
Dim r&, i&, j&, k&
'Application.ScreenUpdating = False
Set sht = ThisWorkbook.Worksheets("CpCode")
Set http = CreateObject("MSXML2.ServerXMLHttp")
'Set http = CreateObject("WinHttp.WinHttpRequest.5.1")
Set JSON = New JsonBag
If http Is Nothing Then Exit Sub
If MsgBox("언론사 코드를 가져오는 것은 시간이 걸립니다. 계속할까요?", vbOKCancel) = vbCancel Then Exit Sub
c = Array("ㄱ", "ㄴ", "ㄷ", "ㄹ", "ㅁ", "ㅂ", "ㅅ", "ㅇ", "ㅈ", "ㅊ", "ㅋ", "ㅌ", "ㅍ", "ㅎ", "기타")
'기존 내용 삭제
r = sht.Cells(sht.Rows.Count, "A").End(xlUp).Row
If r < 1 Then r = 1
sht.Range("A1:B" & r).ClearContents
sht.[A1] = "전체"
k = 2 '2행부터
For i = LBound(c) To UBound(c)
Application.StatusBar = "Loading page: " & i & "..."
url = Worksheets("CONFIG").Range("A1").Text & ENCODEURL(c(i))
'Debug.Print url
With http
.Open "get", url, False
'SetRequestHeader
Dim sLeft$, sRight$, t&
t = Worksheets("CONFIG").UsedRange.Rows.Count
If t < 3 Then MsgBox "check CONFIG sheet": Exit Sub
For j = 4 To t
sLeft = Trim(Split(Worksheets("CONFIG").Cells(j, 1), ":")(0))
sRight = Trim(Split(Worksheets("CONFIG").Cells(j, 1), ":")(1))
'Accept-Encoding은 제외
If Not sLeft Like "*-Encoding" Then .setRequestHeader sLeft, sRight
Next j
.send
str = .responseText 'StrConv(.responseBody, vbFromUnicode)
'Debug.Print str
JSON.JSON = str
End With
If Not JSON.Exists("message") Then MsgBox "Connection failed": Exit Sub
' If JSON("message") <> "success" Then MsgBox "Json Error": Exit Sub
Set JSON = JSON("cp_infos")
For j = 1 To JSON.Count
sht.Cells(k, "A") = JSON(j)("name") '언론사명
sht.Cells(k, "B") = JSON(j)("code") '언론사코드
k = k + 1 '다음 행으로
Next j
Application.Wait (Now + TimeSerial(0, 0, 1))
Next i
Set JSON = Nothing
Set http = Nothing
End Sub
실행결과:

특히 CpCode 코드들을 구하기 위해서는 쿠키값이 필요해서 샘플 쿠키값을 CONFIG시트에 넣어놓고 가져와서 사용했습니다.
또한 값이 JSON 구조로 리턴되기 때문에 JsonBag 클래스를 이용해서 파싱합니다.
현재는 CpCode 시트에 모두 가져왔기 때문에 다시 실행할 필요는 없고 최초 1회만 실행이 필요합니다.
CpCode시트의 언론사 목록들이 언론사를 선택하는 셀을 선택했을 때 유효성검사 목록에 뜨게 됩니다.

또한 발생하는 문제점이 다음 제휴언론사만 검색하는 것이 기본 설정이기 때문에 특정 언론사를 대상으로 해서 검색할 때 해당 언론사의 검색 결과가 0건이 되어 버립니다. 그래서 검색 설정을 '전체' 언론사로 설정해야만 비제휴 언론사에 대해서도 검색이 가능해집니다.
이를 위해서는
전체 검색중이라는 특별한 쿠키값이 계속 유지되어야 합니다.
바로 SHOW_DNS 라는 쿠키값입니다.
개발자 도구에서 쿠키값의 변화를 비교하면서 몇번의 테스트를 해보면
SHOW_DNS=0; 을 포함하면 전체 언론사를 대상으로 검색하는 것으로 보입니다.
또 한 가지 주의할 점은 전체 언론사를 검색 대상으로 검색하면 돌아오는 HTML내용이 기존과 약간 달라집니다.
아래처럼 클래스 이름이나 태그명이 달라집니다.

그래서 아래처럼 특정 언론사를 검색하는 전체 검색인 경우 쿠키 값에 SHOW_DNS=0 값을 보내도록 했습니다.
(일반 검색인 경우는 해당 쿠키 없이 제휴 언론사 범위로 검색합니다.)
Option Explicit
Sub getDaumNews()
Dim sht As Worksheet, shp As Shape
Dim http As Object
Dim doc As MSHTML.HTMLDocument
Dim url$, newsTitle$, newsLink$, newsFrom$, newsDate$, newsThumb$, KeyWord$, sort$, CpName$, CpCode$, sCookie$
Dim i As Long, j As Long, r As Long, p%, Page%
Dim elem As MSHTML.IHTMLDOMChildrenCollection
Dim ele As MSHTML.IHTMLElementCollection
'Application.ScreenUpdating = False
Set sht = ThisWorkbook.Worksheets("Sheet1")
'KeyWord = sht.[B1]
KeyWord = Trim(Sheet1.TextBox1.Text)
If Len(KeyWord) = 0 Then MsgBox "검색어를 입력하세요.", vbInformation: Exit Sub
Page = sht.[C1]
If Page >= 5 Then If MsgBox("여러 페이지 검색은 시간이 걸립니다. 계속할까요?", vbOKCancel) = vbCancel Then Exit Sub
If sht.[E1] = "최신순" Then sort = "recency" Else If [E1] = "오래된순" Then sort = "old" Else sort = "" '"accuracy"
CpName = sht.[F1]
If CpName <> "" And CpName <> "전체" Then
CpCode = WorksheetFunction.VLookup(CpName, Worksheets("CpCode").Range("A:B"), 2, False)
'Debug.Print CpName, CpCode
End If
Set http = CreateObject("MSXML2.ServerXMLHttp")
Set doc = New MSHTML.HTMLDocument
If http Is Nothing Or doc Is Nothing Then Exit Sub
'기존 내용 삭제
r = sht.Cells(sht.Rows.Count, "A").End(xlUp).Row
If r < 3 Then r = 3
sht.Range("A3:J" & r).ClearContents
'기존 썸네일 삭제
With sht.Shapes
For j = .Count To 1 Step -1
If .Item(j).Name Like "Pic_*" Then .Item(j).Delete
Next j
End With
r = 3
For p = 1 To Page
Application.StatusBar = "Loading page: " & p & "..."
'https://m.search.daum.net/search?nil_suggest=btn&w=news&DA=SBC&cluster=y&q=ai&p=1&cp=16grxK7C3CUuztx9Yt&cpname=가톨릭신문
url = "https://m.search.daum.net/search?nil_suggest=btn&w=news&cluster=y&q=" & KeyWord & _
"&p=" & p & IIf(sort = "", "", "&sort=" & sort) & _
IIf(CpCode = "", "", "&cp=" & CpCode & "&cpname=" & ENCODEURL(CpName))
Debug.Print url
With http
.Open "get", url, False
.setRequestHeader "User-Agent", "Mobile" '"Mozilla/5.0 (Linux; Android 6.0;) AppleWebKit/537.36 Chrome/120.0.0.0 Mobile Safari/537.36"
If p = 1 Then 'get Cookie first
'.send
If CpCode <> "" Then
'sCookie = ParseCookie(.getAllResponseHeaders)
'sCookie = sCookie & "; SHOW_DNS=0;" ' 비제휴언론사 포함
sCookie = "SHOW_DNS=0;" ' 비제휴언론사 포함
'Debug.Print sCookie
End If
End If
If CpCode <> "" Then
'.Open "get", url, False
'.setRequestHeader "User-Agent", "Mobile"
.setRequestHeader "Cookie", sCookie
End If
.send
doc.body.innerHTML = .responseText
'Debug.Print .responseText
'Debug.Print Mid(.responseText, InStr(.responseText, "<UL") - 3, 6000)
End With
'각 기사 노드 컬렉션을 추출
If CpCode <> "" Then '전체 기사
Set elem = doc.querySelectorAll(".compo-itemlist > ul > li")
Else '제휴 기사
Set elem = doc.querySelectorAll(".c-list-basic > li")
End If
If elem.Length < 1 Then Exit Sub
For i = 0 To elem.Length - 1
Cells(r, "A") = r - 2 '연번
'언론사
If CpCode <> "" Then newsFrom = elem(i).querySelector(".compo-subinfo > .txt_info").innerText _
Else newsFrom = elem(i).querySelector("strong").innerText '첫번째 strong 태그
Cells(r, "B") = newsFrom
Cells(r, "B").NumberFormat = " @" '왼쪽 한 칸 여백
'날짜
If CpCode <> "" Then newsDate = elem(i).querySelectorAll(".txt_info").Item(1).innerText _
Else newsDate = elem(i).querySelector(".gem-subinfo").innerText
Cells(r, "C") = Split(newsDate, " ")(0)
' 뉴스 제목
If CpCode <> "" Then newsTitle = elem(i).querySelector(".tit-g").innerText _
Else newsTitle = elem(i).querySelector(".item-title").innerText
Cells(r, "D") = newsTitle
Cells(r, "D").NumberFormat = " @"
'뉴스 링크
If CpCode <> "" Then newsLink = elem(i).querySelector("a").href _
Else newsLink = elem(i).querySelector(".item-title > strong > a").href
If newsLink <> "" Then
Cells(r, "F") = newsLink
Cells(r, "F").Hyperlinks.Add Anchor:=Cells(r, "F"), Address:=newsLink, TextToDisplay:=newsLink '링크 삽입 위치
End If
'썸네일
If elem(i).querySelectorAll(".wrap_thumb > a > img").Length > 0 Then
newsThumb = elem(i).querySelector(".wrap_thumb > a > img").getAttribute("data-original-src")
Else
'썸네일 없는 경우 언론사 로고
If CpCode <> "" Then newsThumb = "" _
Else newsThumb = elem(i).querySelector(".wrap_thumb > span > img").getAttribute("data-original-src")
End If
With Cells(r, "E")
If newsThumb <> "" Then
Set shp = sht.Shapes.AddPicture(newsThumb, msoTrue, msoFalse, .Left + 1, .Top + 1, .Width - 2, .Height - 2)
shp.Name = "Pic_" & Format(r - 2, "000")
shp.AlternativeText = newsLink
End If
End With
'잠시 대기
If (r - 2) Mod 3 = 0 Then _
Application.Wait Now + TimeSerial(0, 0, 1)
r = r + 1
Next i
Next p
Application.StatusBar = False
ActiveWindow.ScrollRow = 3 ' 위로 스크롤
Application.ScreenUpdating = True
Set http = Nothing
Set doc = Nothing
End Sub
원래 다음(DAUM)과 비제휴 언론사인 '가톨릭 신문'으로 '인공지능'를 검색하면 0건이 검색되지만

SHOW_DNS=0 을 쿠키로 해서 '전체 '신문사로 검색하도록 하면 아래처럼 검색이 가능해집니다.
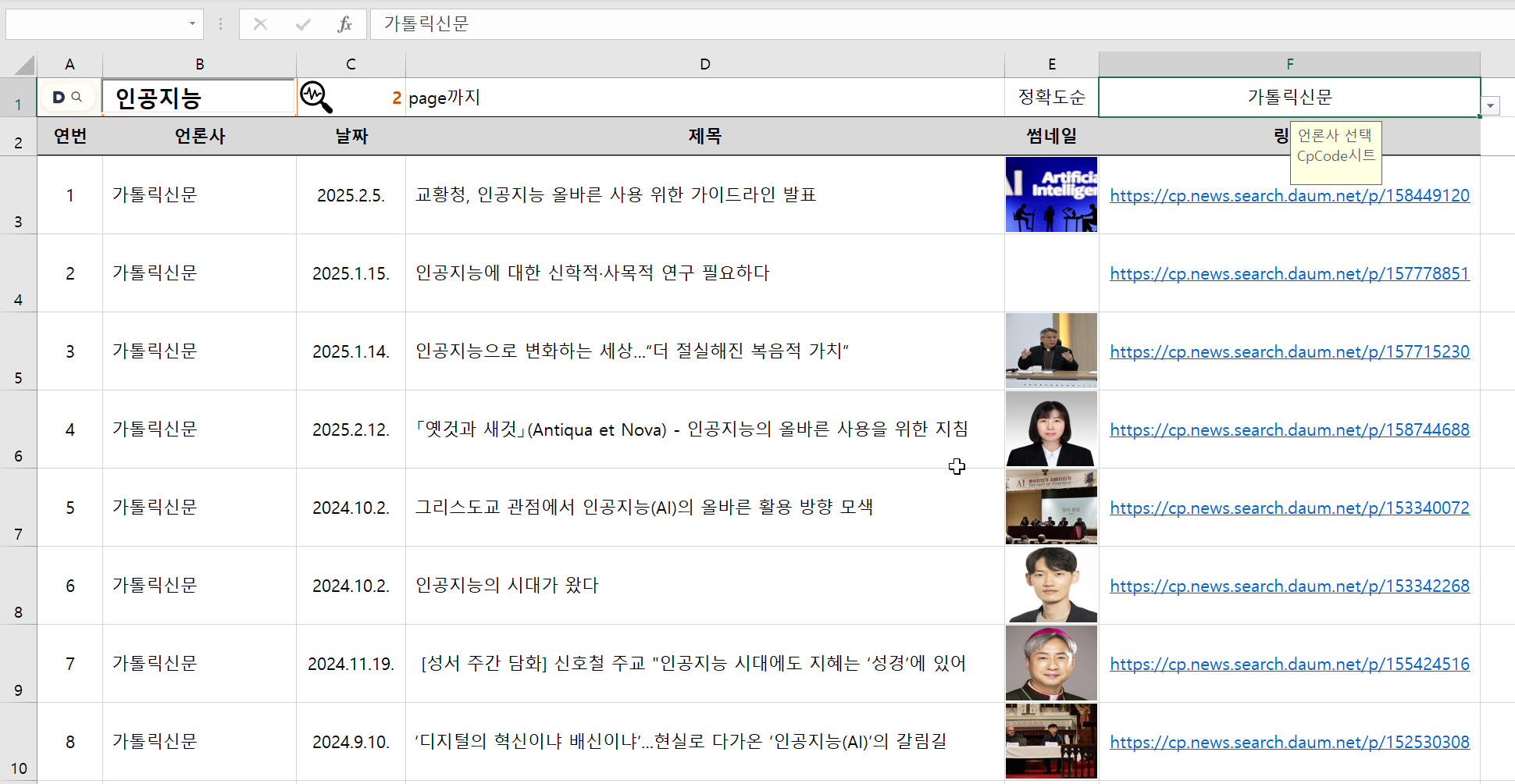
테스트 파일 첨부합니다.
사용방법은
- [B1]셀 위의 텍스트 상자에 검색어를 넣고 <엔터>키를 치면 됩니다.
또는 돋보기 모양 검색 아이콘을 눌러도 됩니다. - [C1]셀에 검색할 페이지 개수를 입력할 수 있습니다.
'다음'은 검색할 때마다 15건씩 검색하는데 2페이지까지 검색하면 30건이 검색됩니다. - [E1]셀은 정확도순, 최근순, 오래된순 을 선택할 수 있습니다.
- [F1]셀에서 전체 혹은 언론사를 선택해서 전체언론사 혹은 특정 언론사를 제한해서 검색이 가능합니다. (SHOW_DNS=0; 쿠키값 설정)

서버에 부담을 덜기 위해 3페이지 마다 1초씩 기다리도록 했습니다.
주의:
- CpCode시트는 언론사 코드를 담고 있어서 삭제시 언론사 검색이 안됩니다.
- 파일을 열면 검색 텍스트 상자로 포커스가 옮겨집니다.
- 검색란에서 <엔터> 키 사용이 가능합니다.
- 썸네일 이미지는 'Pic_"이라는 이름을 갖게 되고 새로 검색하면 삭제됩니다.
- 기본적인 일반 검색은 '다음' 제휴언론사에 한해 검색합니다.
- 특정 언론사를 선택하면 제휴/비제휴 포함 전체 언론사로 검색합니다.
- '다음(DAUM)' 사이트에서 서버 HTML이나 내부 코드 변경이 있을 경우 작동이 되지 않을 수 있습니다. 그 경우 계속적인 유지 보수를 보장하지 않습니다.
경고:
이 게시물은 웹사이트의 내용을 QuerySelector 를 사용하여 가져오는 방법에 대한 개인적 연구 및 교육용 목적으로 작성되었습니다. 이 내용을 바탕으로 '다음(DAUM)' 사이트의 운영에 피해를 주거나 '다음' 에서 원하지 않는 방식으로 악용/남용하는데 이용되어서는 안됩니다.
'XLS+VBA' 카테고리의 다른 글
| VBA로 현재 프린터 단면/양면 인쇄 설정 (1) | 2025.03.02 |
|---|---|
| 체크박스(✅) 확인란 삽입하기 (0) | 2025.01.23 |
| 구글 Gemini API 활용, 일괄로 문장 바꿔 쓰기(Rephrasing) (0) | 2025.01.01 |
| 365 엑셀에서 셀안의 그림(PictureInCell) 기능 (0) | 2024.12.23 |
| 단어의 빈도수 통계내기 (2) | 2024.12.06 |
| WinHttp 한글 인코딩이 깨질 때 처리 방법(예시: 당근 사이트) (0) | 2024.11.18 |
| 의료기기 검색 크롤링 (2) | 2024.10.03 |
| 구글 검색 API > 검색 결과 첫번째 링크 가져오기 (0) | 2024.07.03 |

최근댓글